索引分词架构
架构思路
- ES会将商品名称进行分词,用户在用关键字搜索商品时会按照商品名称拆分出来的内容进行匹配
- 除ES自带的分词词库外,系统还可以自定义分词
ES自动分词
说明
在生成商品索引时,ES会使用自带的IK分词器对商品名称进行分词
IK分词器分词粒度分为:ik_max_word和ik_smart
ik_max_word:会将文本做最细粒度(拆到不能再拆)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合ik_smart:会将文本做最粗粒度(能一次拆分就不两次拆分)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」,此种分词粒度属于智能分词
现在Javashop系统内使用的是ik_smart
数据库设计
ES将商品名称分词后,会将相关数据保存至数据库中
表名:es_goods_words
| 字段名 | 类型与长度 | 备注 |
|---|---|---|
| id | bigint(20) | 主键ID |
| words | varchar(255) | 分词名称 |
| goods_num | int(10) | 数量 |
| quanpin | varchar(255) | 全拼字母 |
| szm | varchar(255) | 首字母 |
| type | varchar(20) | 类型(SYSTEM:系统,PLATFORM:平台) |
| sort | int(10) | 排序值 |
代码展示
分词
com.enation.app.javashop.framework.elasticsearch.ElasticOperationUtil#analyzer
/**
* 分词
* @param jestClient jest客户端
* @param txt 待分词数据
* @return
*/
public static List<String> analyzer(JestClient jestClient,String txt) {
List<String> result = new ArrayList<>();
Analyze analyze = new Analyze.Builder().text(txt).analyzer("ik_smart").build();
JestResult jestResult = execute(jestClient,analyze);
jestResult.getJsonObject().get("tokens").getAsJsonArray().forEach( token -> {
result.add(token.getAsJsonObject().get("token").getAsString());
});
return result;
}
入库
com.enation.app.javashop.service.goodssearch.impl.GoodsIndexManagerImpl#wordsToDb
/**
* 将分词结果写入数据库
*
* @param wordsList
*/
protected void wordsToDb(List<String> wordsList) {
//去掉重复数据
wordsList = removeDuplicate(wordsList);
//入库
goodsWordsManager.addWordsBatch(wordsList);
}
/**
* list去重
*
* @param list
* @return
*/
protected List<String> removeDuplicate(List<String> list) {
List<String> listTemp = new ArrayList();
for (String words : list) {
if (!listTemp.contains(words)) {
listTemp.add(words);
}
}
return listTemp;
}
com.enation.app.javashop.service.goodssearch.impl.GoodsWordsManagerImpl#addWordsBatch
/**
* 批量入库
* @param wordsList 分词数据集合
*/
@Override
public void addWordsBatch(List<String> wordsList) {
if(wordsList.isEmpty()){
return;
}
List<GoodsWordsDO> dbList = new QueryChainWrapper<>(goodsWordsMapper).in("words", wordsList).list();
//需要新增的
List<String> collect = dbList.stream().map(GoodsWordsDO::getWords).collect(Collectors.toList());
List<String> needAddList = wordsList.stream().filter(words -> !collect.contains(words)).collect(Collectors.toList());
List<GoodsWordsDO> needAdd = needAddList.stream().map(words -> {
//不存在,则添加
GoodsWordsDO goodsWordsDO = new GoodsWordsDO();
goodsWordsDO.setGoodsNum(1L);
goodsWordsDO.setQuanpin(PinYinUtil.getPingYin(words));
goodsWordsDO.setSort(0);
goodsWordsDO.setSzm(PinYinUtil.getPinYinHeadChar(words));
goodsWordsDO.setType(GoodsWordsType.SYSTEM.name());
goodsWordsDO.setWords(words);
return goodsWordsDO;
}).collect(Collectors.toList());
saveBatch(needAdd);
if(collect.size() > 0){
//修改已存在的,数量+1
update().setSql("goods_num = goods_num + 1").in("words", collect).update();
}
}
自定义分词
描述
- 可以在管理端 -> 运营 -> 搜索 -> 搜索分词中对关键词进行维护
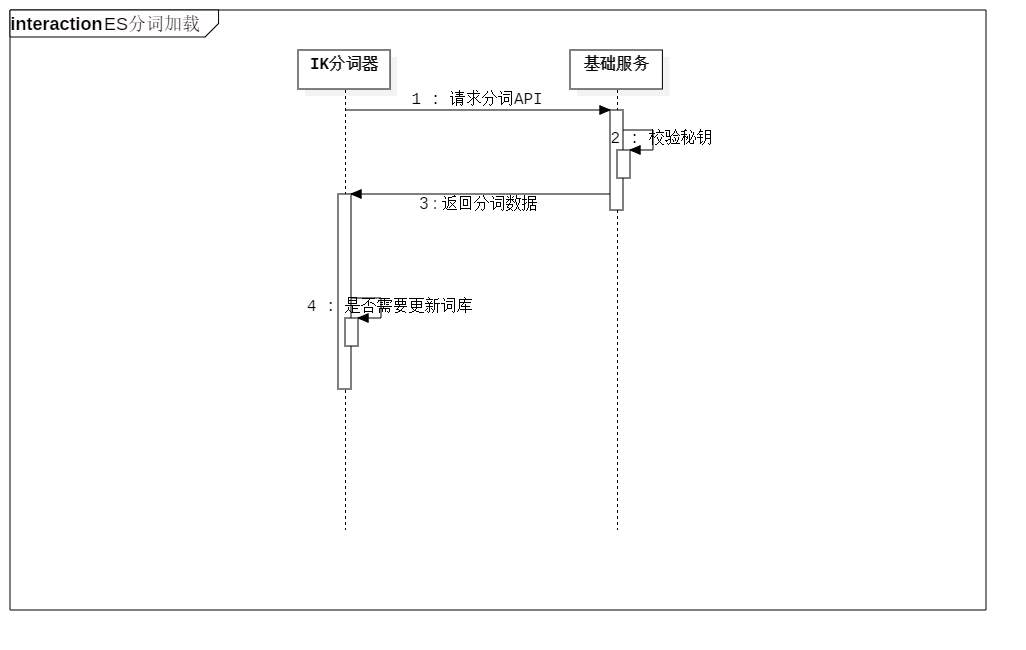
- 添加自定义分词之前要先设置秘钥(此秘钥仅做加载分词API验证使用),此秘钥是在部署ES时设置的
秘钥
在部署ES时,我们可以自定义es安装目录下/plugins/ik/config/IKAnalyzer.cfg.xml这个文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://api.base.test.com/base/load-customwords?secret_key=secret_value</entry>
</properties>
其中的secret_value就是我们的秘钥,需要我们自己去设置
时序图
数据结构
存储自定义分词的数据库表名:es_custom_words
| 字段名 | 提示文字 | 类型 | 长度 | 是否主键 |
|---|---|---|---|---|
| id | id | int | 10 | 是 |
| name | 关键词 | 字符串 | 100 | 否 |
| add_time | 添加时间 | 长整型 | 20 | 否 |
| modify_time | 最后修改时间 | 长整型 | 20 | 否 |
| disabled | 是否可用:可用:1 ;隐藏: 0 | 整形 | 1 | 否 |
秘钥设置说明: 在系统设置表(es_setting)中新增分组(ES_SIGN),对秘钥进行维护时修改此分组下的数据。
类图展示
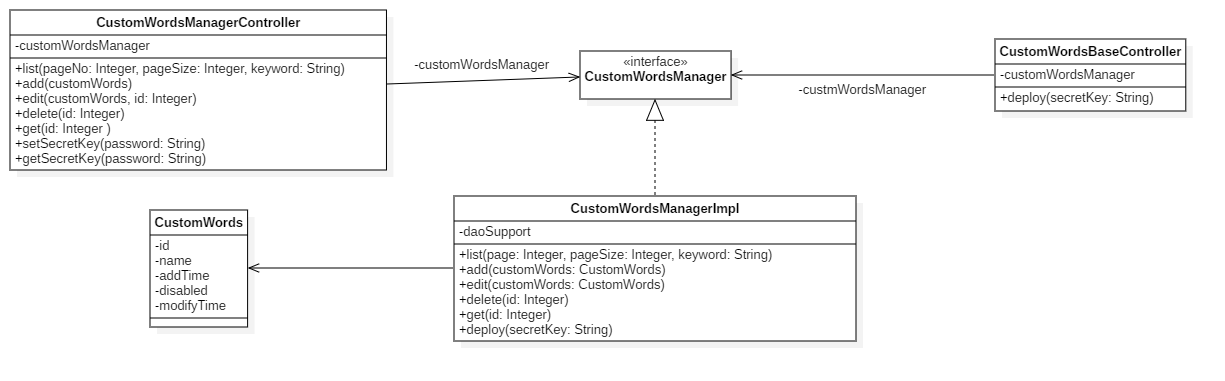
CustomWords说明:
| 属性 | 说明 | 备注 |
|---|---|---|
| id | id | |
| name | 分词名称必填 | |
| addTime | 添加时间 | |
| disabled | 是否可用 | 可用:1;不可用:0 |
| modifyTime | 修改时间 |
代码展示
加载自定义分词
com.enation.app.javashop.api.base.CustomWordsBaseController#getCustomWords
@GetMapping
@Parameters({
@Parameter(name = "secret_key", description = "秘钥", required =true, in=ParameterIn.QUERY)
})
public String getCustomWords(@Parameter(hidden = true) String secretKey){
if(StringUtil.isEmpty(secretKey)){
return "";
}
String value = settingClient.get(SettingGroup.ES_SIGN);
if(StringUtil.isEmpty(value)){
return "";
}
EsSecretSetting secretSetting = JsonUtil.jsonToObject(value,EsSecretSetting.class);
if(!secretKey.equals(secretSetting.getSecretKey())){
throw new ServiceException(GoodsErrorCode.E310.code(),"秘钥验证失败!");
}
String res = this.customWordsManager.deploy();
try {
return new String(res.getBytes(),"utf-8");
}catch (Exception e){
e.printStackTrace();
}
return "";
}
com.enation.app.javashop.service.goodssearch.impl.CustomWordsManagerImpl#deploy
@Override
public String deploy() {
List<CustomWords> list = this.customWordsMapper.selectList(new QueryWrapper<CustomWords>()
.eq("disabled",1)
.orderByDesc("modify_time"));
HttpServletResponse response = ThreadContextHolder.getHttpResponse();
StringBuffer buffer = new StringBuffer();
if (StringUtil.isNotEmpty(list)) {
int i = 0;
for (CustomWords word : list) {
if (i == 0) {
SimpleDateFormat format = new SimpleDateFormat( "yyyy-MM-dd hh:mm:ss" );
try {
response.setHeader("Last-Modified", format.parse(DateUtil.toString(word.getAddTime(),"yyyy-MM-dd hh:mm:ss")) + "");
response.setHeader("ETag", format.parse(DateUtil.toString(word.getModifyTime(),"yyyy-MM-dd hh:mm:ss")) + "");
}catch (Exception e){
e.printStackTrace();
}
buffer.append(word.getName());
} else {
buffer.append("\n" + word.getName());
}
i++;
}
}
return buffer.toString();
}